A $537 Local LLM Machine
The Setup
Over the holidays, I bought a refurbished Miniforum UM790 Pro with 64GB RAM and 1TB NvME for $537 with free shipping. The CPU is an AMD Ryzen 9 7940HS with AMD Radeon 780M GPU. The first thing I did was to remove the wifi+bt card. I then fought with the PSID and enabled OPAL drive encryption. After that, installed OpenBSD. It works flawlessly.
After fighting with llama.cpp in OpenBSD, I setup a few models with Ollama in Linux, to try the same query and test the results. Since not everyone is a command-line lover, I set up Open Web UI for everyone else. Everything runs locally without Internet access.
Performance
I read that users need massive hardware and super expensive GPUs to even consider running local models. Yes, all that would be fantastic in some world that is not mine. The models run roughly at 5 to 20 tokens per second. A GPU runs from 50 to 100 tokens a second. Performance also depends on the prompt complexity. The typical mode of usage is to pick the model, submit the prompt, and go do something else for a minute. I don't have an average for how long prompts take to answer, but it's about 30 seconds from when the response finishes.
The AMD Ryzen 9 7040HS has an NPU inside. It's called "AMD Ryzen™ AI" and runs at "10 TOPS". The forthcoming Linux kernel, 6.14, should include the kernel modules to enable using this NPU (AMDXDNA as it is called). I"m hoping when this new linux kernel is released, the LLM model performance improves. However, I can live with it now.
As for testing, I've compared the results between duck.ai, various Anthropic Claude models, and the local machine. Obviously, duck.ai and claude are faster in their response, but the results are the same. Here's the comparison:
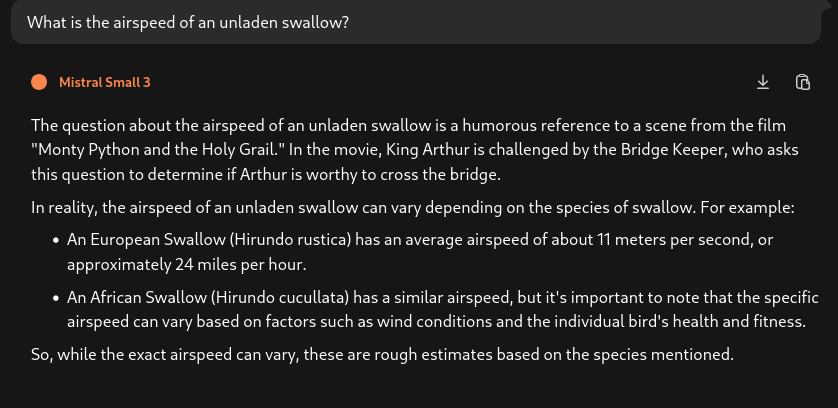
We're running the same model in both cases. The duck.ai response is nearly instant. The local LLM took 1.2 seconds at prompt token 73.77 tokens/second, response token 13.8 tokens/second. Not bad for a CPU-based LLM engine.
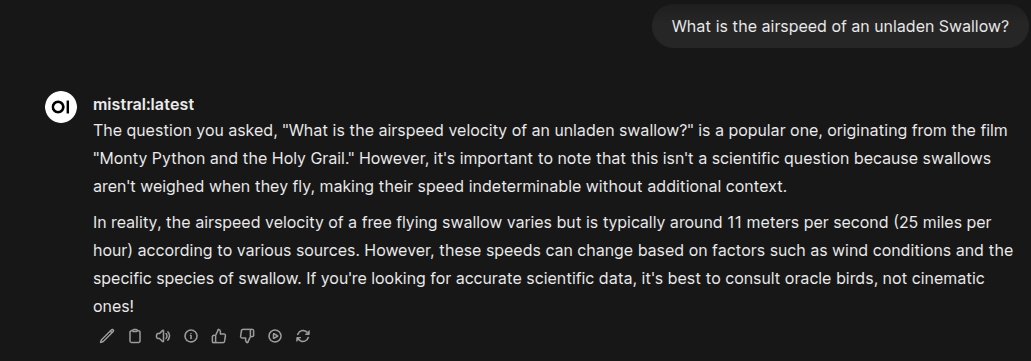
Let's try another, in theory, more difficult question:
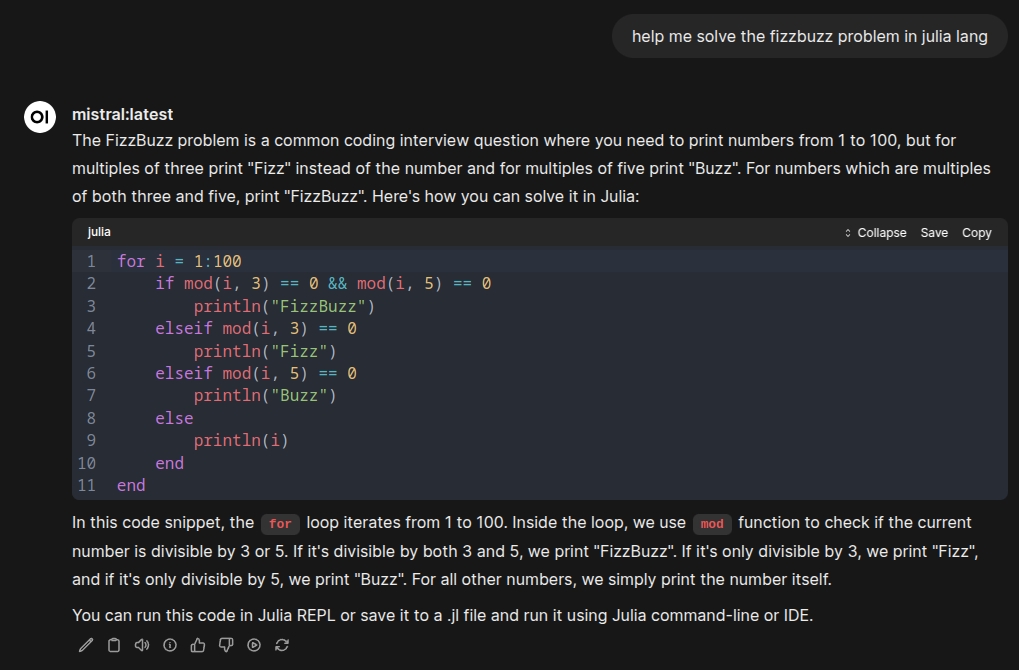
Duck.ai was instant, as expected. The local LLM took 3 seconds to finish the response, with a response token rate of 12.96 tokens/second, and prompt tokens per second at 60.03. Slower, slightly more complex, but still 3 seconds is fast enough for my needs.
I could continue, but the point is while the local LLM is slower, the responses are the same. You can run a local LLM model on cheap hardware. Would I like a fast GPU? Of course. Do I need a fast GPU to use an offline LLM? No.