Building a LLM in pure Rust, Part 2
See Part 1. After spending too much time trying to train a model with my own blog posts, I realized I can't train the model to both learn English and my writing style at the same time.
While I was building the model, I ran into an issue with Burn. No matter what I did, during the pre-training on the Gutenberg datasets, there was a 1.2 - 2.0 second lag when the collation and compilation of the tokens were being prepped for the GPU phase of the training. The problem was probably Burn/CubeCL's eager-mode execution model and runtime abstraction overhead. It took me way too long to figure out what was slowing down the model building. I think it is:
Burn 0.21 uses CubeCL as its device-agnostic compute layer. CubeCL compiles a Rust-flavored IR down to CUDA (or WGSL, etc.) at runtime. In eager mode, every single operation (matmul, softmax, gelu, etc.) has to:
- Be traced into an intermediate representation
- Be lowered / optimized
- Be dispatched through CubeCL's runtime to the CUDA driver
That generates a large amount of host-side CPU work between GPU kernel launches. Candle, by contrast, uses cudarc to call cuBLAS and its own handwritten CUDA kernels directly, with no cross-backend IR or graph building.
That's what I think, I'm probably not correct. Kimi 2.6 looked at my code, here's what it thinks is the issue:
Burn 0.21's cubecl-cuda 0.10 backend was spending that ~1.2 s per step on the CPU doing a combination of these things:
1. Runtime IR compilation — CubeCL generates an intermediate representation for every operation and compiles it down to PTX/Cubin at runtime. This is CPU-bound compiler work happening between each tiny kernel launch.
2. Eager-mode autodiff graph construction — Burn builds the backward computation graph dynamically during the forward pass. On every single op (matmul, gelu, layer_norm), the framework traces tensor provenance and records nodes on the host (Rust side) to know what to differentiate later. That's a lot of host-side data structure manipulation.
3. Memory management & staging — Allocating CUDA buffers, tracking tensor lifetimes in memory pools, and staging host-to-device transfers. CubeCL's 0.10 backend apparently did a lot of host-side bookkeeping every step instead of reusing buffers efficiently.
4. Dispatch overhead & sync points — The CPU was likely not just launching kernels asynchronously into a CUDA stream; it was building lists of operations, doing Rust-side dispatch, and possibly forcing unnecessary cudaDeviceSynchronize() calls or other sync points so the abstraction layer could maintain correctness guarantees.
The GPU was idle because the CPU was stuck in framework bookkeeping (graph tracing, buffer management, and per-op compilation) instead of feeding the GPU a continuous stream of work. Candle avoids all of this by using direct cudarc kernel calls with no intermediate graph or per-op IR compilation.
Burn started off at 2 seconds per step, I got it down to 1.2 seconds. No matter the CPU and GPU, it was 1.2 seconds per iteration. At 30k or 54k iterations, 1.2s takes a long time to finish. Burn's support is Discord. No, I'm not going to join your Discord.
However, I switched everything to Candle. Candle uses the C++ library for torch to use the GPU in a constant stream of data. The biggest difference is Candle calls cuBLAS directly and load everything into the GPU for processing. After lots of code, here's what Kimi 2.6 claims is the difference:
Each line is a direct GPU operation dispatched immediately. Candle’s CPU does minimal bookkeeping, so the host has time to keep the GPU pipeline full. That is how Candle achieves ~46 ms/step and 99% utilization versus Burn’s ~1,200 ms and 0%.
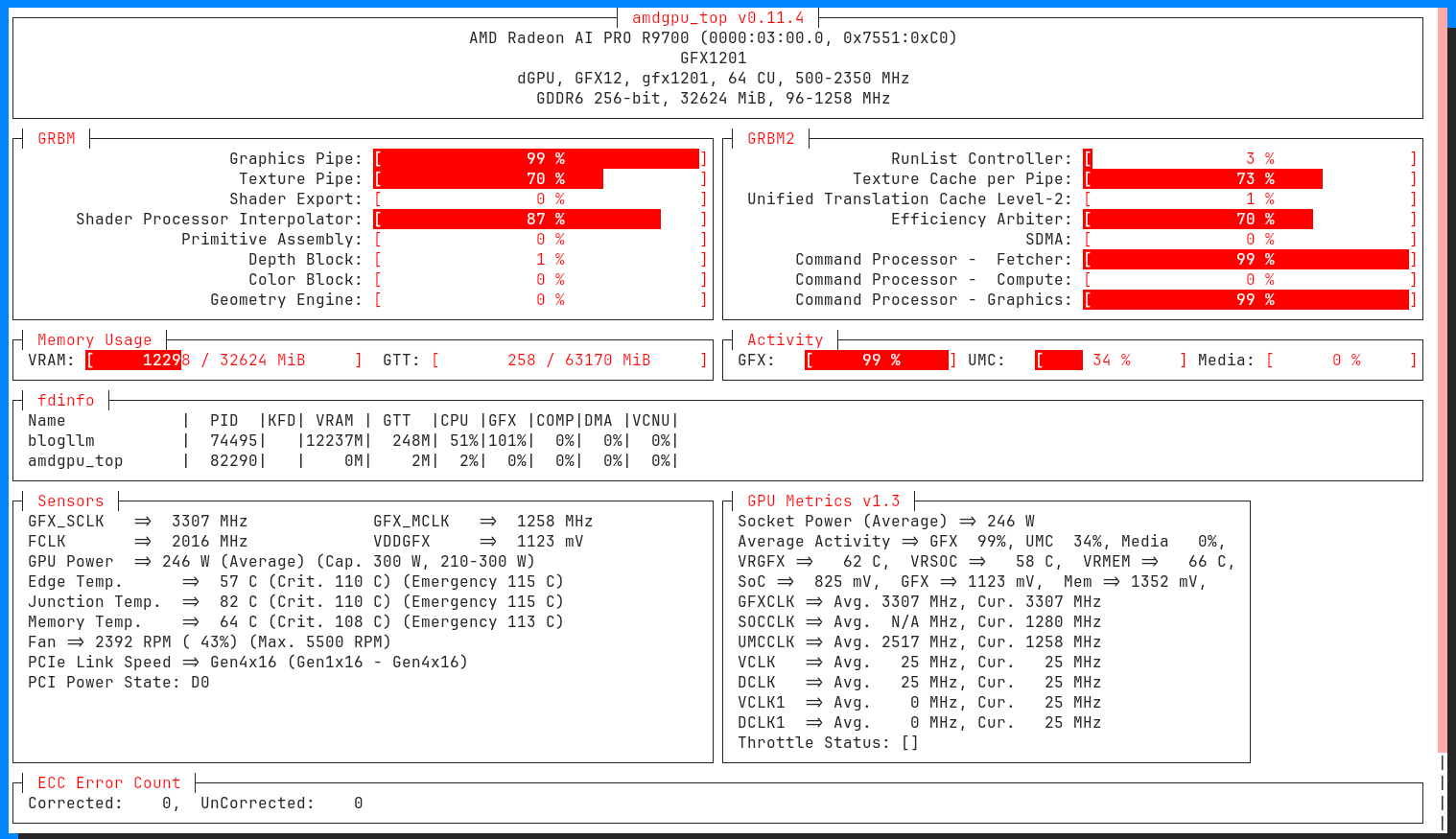
Everything went much quicker, down to 15-20 minutes per each Epoch (30k iterations). In order to speed up the process, I rented some GPUs.
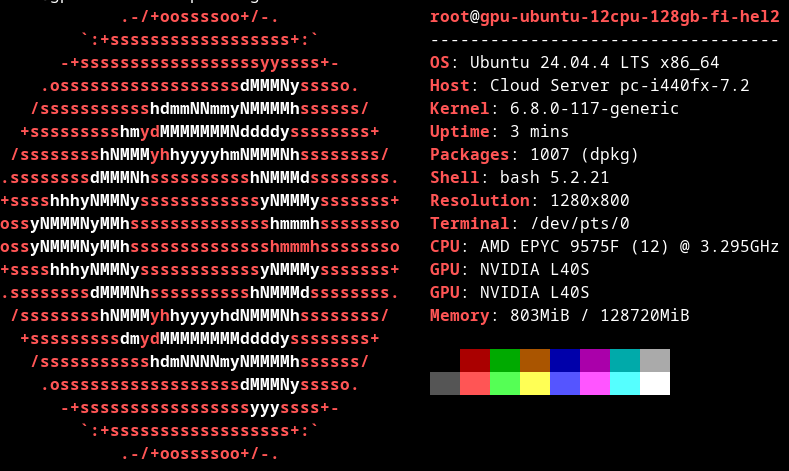
The first machine was powered by 100% hydropower and was dual Nvidia L40S GPUs. I used it to pretrain the model on one GPU, and after a few epochs of pretraining, I started finetuning the model on the second GPU. Again, speedrunning every AI startup from first principles.
After a few cycles of training, generation was much better, but kept failing overall. After burying the GPUs for a while, the provider asked if I wanted to upgrade. Since dual L40S were the best I could get, I agreed.
Within a few hours, a new server appeared.
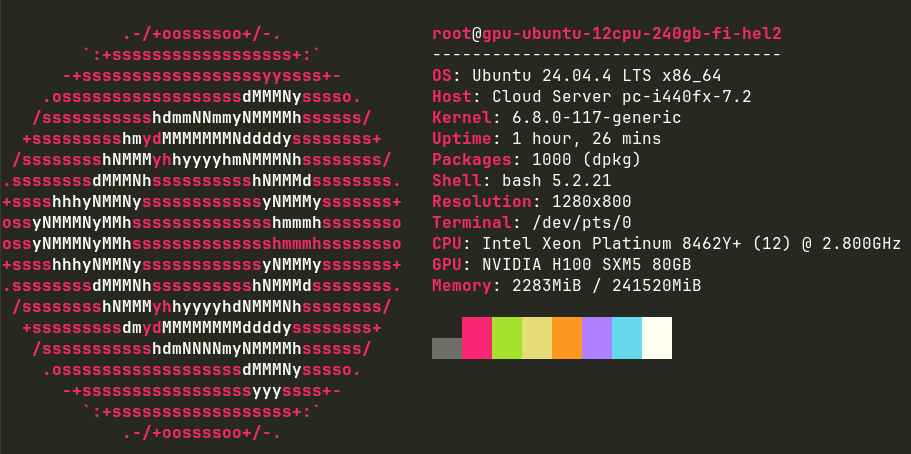
As the screenshot shows, a Xeon Platinum with an Nvidia H100 GPU. This system was much, much faster at everything. The AMD EPYC was fast, but the limit was the GPU. The H100 blasted through pretraining and finetuning in mere hours. However, in the end, the generation of text was still horrible. It was now grammatically correct, but still just one step above jibberish --which matches most of my blog content.
In analyzing the blog content, 50% of the content is down to 1 blog post. Taking out that one post, which isn't even my content, reduces the training data to 273 kb of text. This is way too little to train a model on its own. It works better when I do a RAG into an existing model.
The git repo sits in stasis for now. I need to work on automating the RAG through an existing model. Or, I need to figure out how to train a small model on a very small text sample. Fun and challenges abound.
As I was looking for GPUs to buy or rent, we run into companies that exist solely to buy up GPUs from Nvidia and rent to you the user. In doing some basic research, aka looking at the investor/news sections of these company's site, Nvidia Ventures, Supermicro, and other hardware companies are funding the GPU renters. The GPU renters are then buying the GPUs and servers from their very investors. I'm sure there's some legal separation there. What do I know, it seems a snake eating its tail to me. An H100 or MI350x would be great to own, but they are ridiculously expensive ($30k to start) and consume a ton of power (600W or more). In roughly 3 to 6 months time, you could buy the hardware. The bet is that in that 3-6 months, there's a 2x increase in GPU processing power at the same power usage, so buying the hardware is a poor choice.
The non-GPU providers seem to be going with lots of small cores, well connected to create massive meshes of cores. The idea is you can combine multiple cards, cards full of servers, servers with servers to create one massive GPU-looking thing to a process. Or, one massively parallel set of matrix math processors to a process or many. Some put lots of cores into a single wafer versus hundreds of chips across boards/servers.
The world really needs a better way to process matrix math that doesn't consume endless power. Or maybe guessing next token isn't the end game for AI.
