Parsing 500 GB of Logs with Ruby Every Day

I'm working on a research project where we're parsing 500-750GB of log data per day. Initially, the hack was to use fish shell scripts to automate grep, awk, etc. Quickly, we realized the entire idea of parsing logs every day was insane. However, we lack the resources and time to properly parse the data in near real time. We also log more than we need now, figuring if we have to go back and re-analyze the log data, we'll at least have it stored in an archive. We've already had to go back and re-analyze the logs twice. And compressing and storing the logs is cheaper than reworking the entire experiment to run real-time log parsing.
I wrote some ruby scripts to parse the logs and write out the data we needed. During this experiment, we ran into situations where non-ASCII and non-UTF-8 characters are dumped to the log file. These characters cause the parser to quit. I added some more loops to handle the data and re-encode the data into something we can handle. It turns out, this was painfully slow. Here's the working, but slow, code.
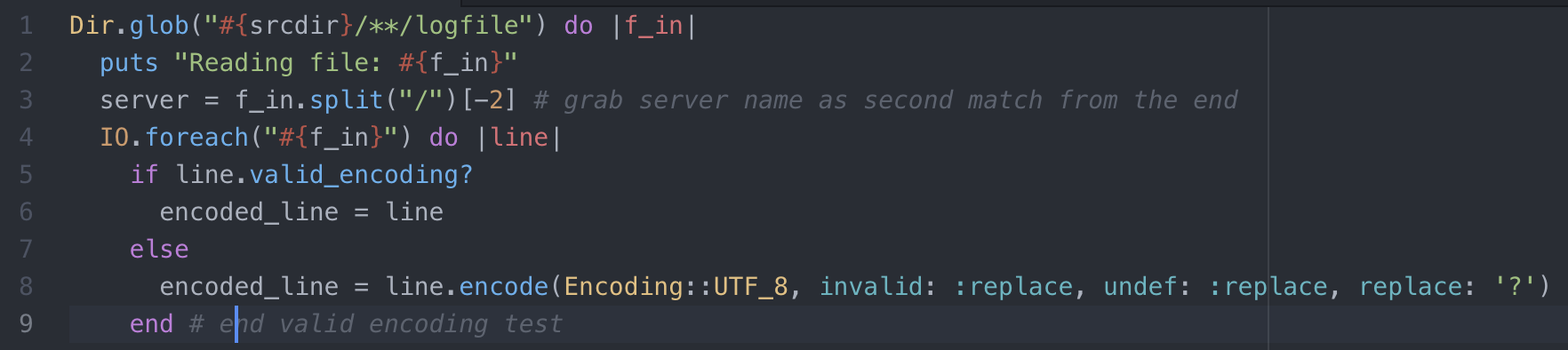
Dir.glob("#{srcdir}/**/logfile") do |f_in|
puts "Reading file: #{f_in}"
server = f_in.split("/")[-2] # grab server name as second match from the end
IO.foreach("#{f_in}") do |line|
if line.valid_encoding?
encoded_line = line
else
encoded_line = line.encode(Encoding::UTF_8, invalid: :replace, undef: :replace, replace: '?')
end # end valid encoding test
On a fairly fast disk array, the parsing takes 1 hour and 45 minutes to finish all of the log files. It seems there is a lot of time spent reading the log line, testing for encoding, and moving through the loop.
After further investigation, we fixed the code generating the invalid characters. Going forward, we should only have valid characters in the log files for parsing. What to do about the past history? It turns out, there are only 5,284 log lines with invalid characters. With the magic of ruby's gsub, we simply replaced the invalid characters with valid ones.
Now we can analyze the billion log lines without worry. Here's the improved parsing code.
Dir.glob("#{srcdir}/**/logfile") do |f_in|
puts "Reading file: #{f_in}"
server = f_in.split("/")[-2] # grab server name as second match from the end
IO.foreach("#{f_in}").grep(/^#{yesterday}/) do |line|
if line.match?(/^#{yesterday}/) && line.match?(/term/)
Much simpler and faster. The script now runs in 17 minutes against all 500+ GB of log files.
I don't know why Wordpress messes up the formatting, just assume it's properly formatted in real life. Here's how it looks inside my code editor.