Fun with this blog, sqlite, basic coding skills

This blog is written/created with Publii. It's an open source, static content management system which is point and click easy to use. After years of Jekyll and Wordpress, migrating to something easy made sense for me. It produces good looking pages which render quickly in every browser. I ran into an old post which linked to an old blog address, blog.lewman.is. I update the post in question to fix the link to blog.lewman.com.
A Simple Question
"I wonder how many posts also have links to my old domain?"
Well, I could manually go through all 781 posts, or since the CMS is open source, just figure it out via code.
Publii is basically HTML, Javascript, and related web technologies. Here's the github breakdown:

The simple directory structure in the filesystem makes it pretty easy to figure out what does what and which parts go where. The best thing is the content is stored in a SQLite database. SQLite deserves its own post because it's such an amazing project and database. However, I'll postpone my SQLite love letter for now.
What can we do with SQLite?
The content for the blog is stored in a file called db.sqlite. Using native tools, the command sqlite3 db.sqlite will open up the database and wait for a command. First off, since the database is just a file, I made a copy and did some exploring and updates in the copy of the database. The reason I did this is that if I completely screwed up the database, the original was still intact and functional. In reality, I ran sqlite3 blog-db-copy.sqlite on my copy of the database.
sqlite3 blog-db-copy.sqliteSQLite version 3.28.0 2019-04-15 14:49:49Enter ".help" for usage hints.
Ok, we're in. We need to know what tables exist in the database. We type the command .tables
sqlite> .tablesauthors posts_additional_data posts_tagsposts posts_images tags
Of those tables, posts, seems the likely candidate for the posts of the blog. What structure does it have? We type the command .schema posts.
sqlite> .schema postsCREATE TABLE IF NOT EXISTS 'posts' ('id' INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, 'title' TEXT, 'authors' TEXT, 'slug' TEXT, 'text' TEXT, 'featured_image_id' INTEGER, 'created_at' DATETIME, 'modified_at' DATETIME, 'status' TEXT, 'template' TEXT);
If you're not familiar with the structure of a SQL table, there's a lot to unpack there. Let's make it simple, the columns are id, title, authors, slug, text, featured_image_id, created_at, modified_at, status, and template. Well, text looks like the most obvious place to find the text content of each post. Let's see what's in each row that contains blog.lewman.is.
sqlite> select * from posts where text like '%blog.lewman.is%';
97|Migrated to Silvrback|1|migrated-to-silvrback|<p>## The new blog</p><p>I signed up with <a href="https://www.silvrback.com/">silvrback</a> blogging platform. It's simple, it's Markdown, it's cheap. I'm still migrating the old blog posts over to the <a href="http://blog.lewman.is">new blog</a>. The migration is a work in progress, but it's making progress fairly quickly.</p><p>## Why Silvrback?</p>
I've spared you the pages and pages of output. The columns in the row are delimited by the | character. So we have id is 97, title is Migrated to Silvrback, authors is 1, slug is migrated-to-silvrback, text is what you see as raw HTML, and further in the output are the rest of the columns. And then repeat this for 16 posts. How do I know there are 16 posts with blog.lewman.is in the text field? Another sql query shows the count.
sqlite> select count(*) from posts where text like '%blog.lewman.is%';
16
Let's find the id, and title of the 16 posts, since we don't really need the full text and everything else for the next steps.
sqlite> select id, title from posts where text like '%blog.lewman.is%';97|Migrated to Silvrback107|Male Genital Mutilation121|In New York City as in Cairo132|A Year with the Oppo N1 and Cyanogenmod135|Joining the Board of Directors of Emerge139|Past Experiments with Fastly, Cloudflare, Bittorrent Sync, and Tor Website Mirrors143|Bike Commuting Pants: Outlier vs. Levi193|A One Year Journey to a Folding Bike: Part Two205|4th of July Hike at Quabbin207|Questions for Successful Dark Web Investigation Businesses240|My low-sugar, high-fiber diet experience258|90 Days with the Tern Folding Bike275|A Year without a Car359|More thoughts on Prometheus360|Upcoming Speaking Engagements in Early 2017627|Speaking Engagements
Ok, now 16 posts is pretty easy to update manually. I have the title of the post and the id number assigned to each post. I can just go into each post content, find the old domain name and update the link. Or we could update the domain in the text since it's all in the database anyway.
Updating text with the SQL language can be a challenge. Fortunately, SQLite makes this easy.
sqlite> update posts set text = replace(text, 'blog.lewman.is', 'blog.lewman.com');
You can almost read that command as plain English. Update the table posts setting the text column/field, replacing blog.lewman.is with blog.lewman.com. I predicted updating 16 posts manually is five minutes of work. That command ran successfully in under a second. Let's run our search again.
sqlite> select id, title from posts where text like '%blog.lewman.is%';
No results. This means we've successfully updated the text field in all posts. Sweet. Trust but verify.
sqlite> select count(id) from posts where text like '%blog.lewman.com%';16
There, 16 posts have the correct domain name now. Just to double verify we updated the correct posts.
sqlite> select id, title from posts where text like '%blog.lewman.com%';97|Migrated to Silvrback107|Male Genital Mutilation121|In New York City as in Cairo132|A Year with the Oppo N1 and Cyanogenmod135|Joining the Board of Directors of Emerge139|Past Experiments with Fastly, Cloudflare, Bittorrent Sync, and Tor Website Mirrors143|Bike Commuting Pants: Outlier vs. Levi193|A One Year Journey to a Folding Bike: Part Two205|4th of July Hike at Quabbin207|Questions for Successful Dark Web Investigation Businesses240|My low-sugar, high-fiber diet experience258|90 Days with the Tern Folding Bike275|A Year without a Car359|More thoughts on Prometheus360|Upcoming Speaking Engagements in Early 2017627|Speaking Engagements
And we're done. I copied the blog-db-copy.sqlite file to db.sqlite and fired up Publii. If you're reading this, everything worked as expected.
How else could we accomplish the same result?
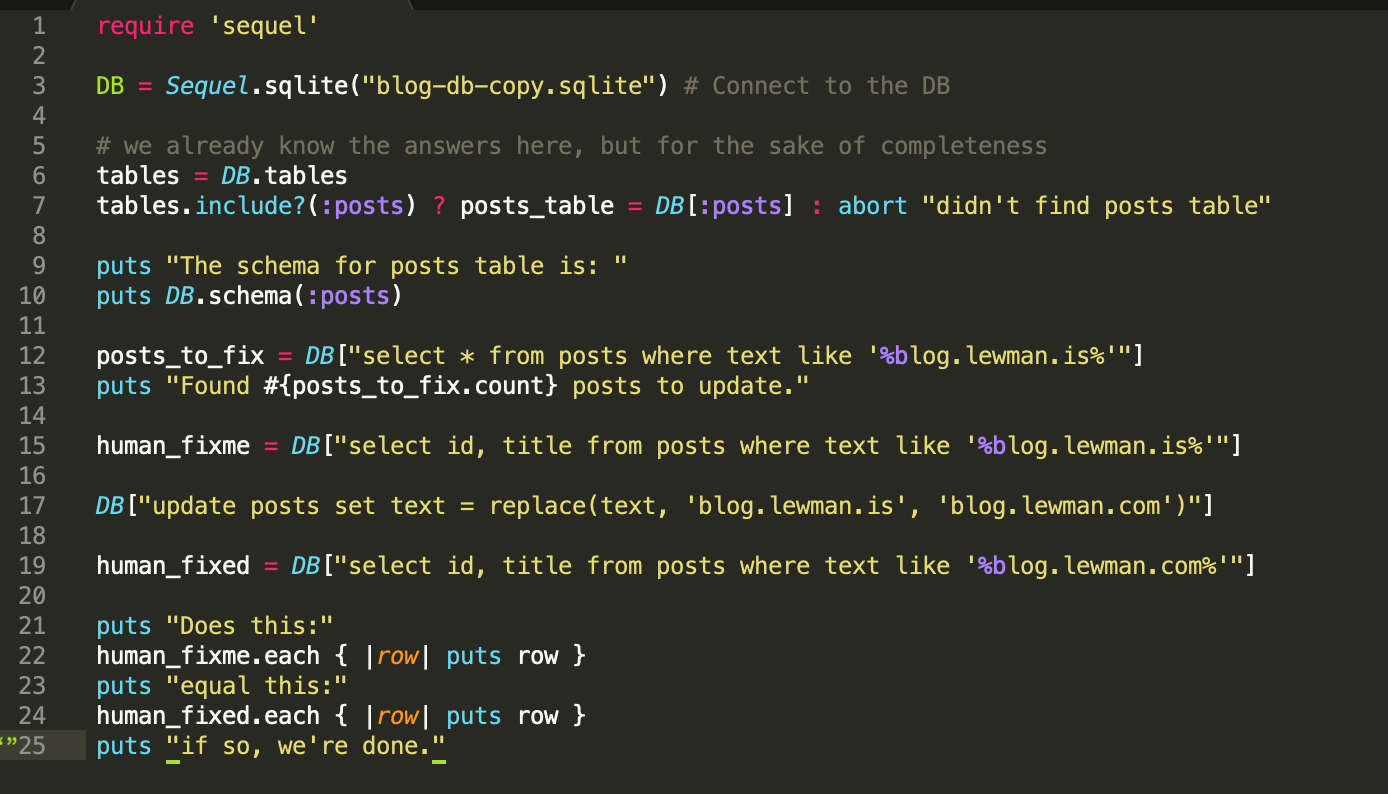
Let's do some basic code design using Ruby. I wanted to spend about five minutes writing this up, otherwise, we're spending more time writing ruby than we could just finish in SQL.
require 'sequel'
DB = Sequel.sqlite("blog-db-copy.sqlite") # Connect to the DB
# we already know the answers here, but for the sake of completeness
tables = DB.tables
tables.include?(:posts) ? posts_table = DB[:posts] : abort "didn't find posts table"
puts "The schema for posts table is: "
puts DB.schema(:posts)
posts_to_fix = DB["select * from posts where text like '%blog.lewman.is%'"]
puts "Found #{posts_to_fix.count} posts to update."
human_fixme = DB["select id, title from posts where text like '%blog.lewman.is%'"]
DB["update posts set text = replace(text, 'blog.lewman.is', 'blog.lewman.com')"]
human_fixed = DB["select id, title from posts where text like '%blog.lewman.com%'"]
puts "Does this:"
human_fixme.each { |row| puts row }
puts "equal this:"
human_fixed.each { |row| puts row }
puts "if so, we're done."puts "if so, we're done."
If I wanted to spend more time, I could convert the datasets human_fixme and human_fixed to arrays, walk the arrays to compare the id numbers and titles match and just print out a short "it worked, we're done." statement. I think you get the general idea.
Even more time and I could use native Sequel statements instead of raw SQL. Something like:
posts_to_fix = posts_table.where(text: /blog.lewman.is/)
Just a simple solution to avoid manual labor and spend a few minutes updating 16 posts with a single SQL command.
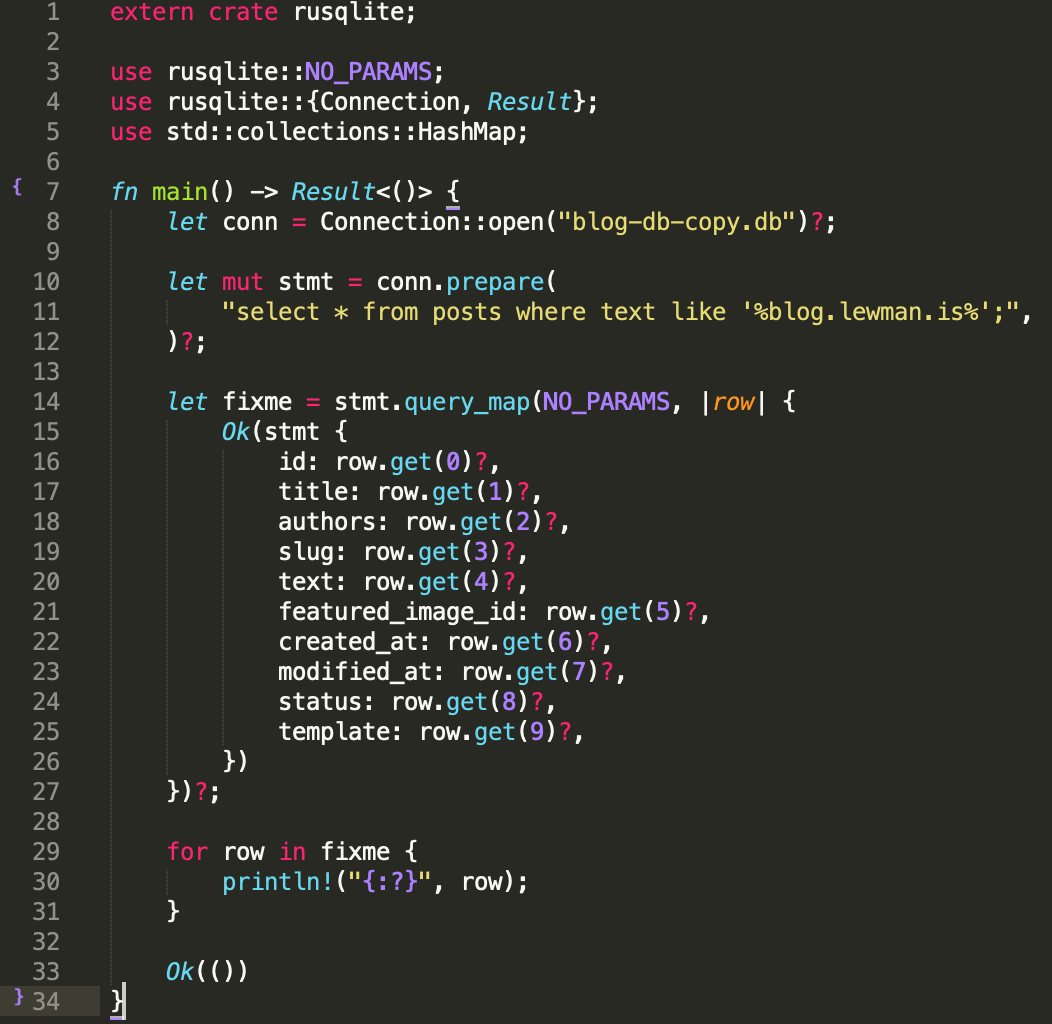
Another option is to do this in Rust. I don't know Rust well enough to simply whip up some code in under 5 minutes. Maybe in 5 hours. ;). A future challenge for me to complete when I know more of the language. Probably something like this to start:
extern crate rusqlite;use rusqlite::NO_PARAMS;use rusqlite::{Connection, Result};use std::collections::HashMap;fn main() -> Result<()> { let conn = Connection::open("blog-db-copy.db")?; let mut stmt = conn.prepare( "select * from posts where text like '%blog.lewman.is%';", )?; let fixme = stmt.query_map(NO_PARAMS, |row| { Ok(stmt { id: row.get(0)?, title: row.get(1)?, authors: row.get(2)?, slug: row.get(3)?, text: row.get(4)?, featured_image_id: row.get(5)?, created_at: row.get(6)?, modified_at: row.get(7)?, status: row.get(8)?, template: row.get(9)?, }) })?; for row in fixme { println!("{:?}", row); } Ok(())}