The 8 Petabyte Challenge
The Discovery
Say you're at work and stumble across a file system with 8 petabytes of log files. How do you start to analyze the data?
TL;DR: There is no answer. But we walk through the process from first principles.
First off, 8 PB is a huge amount of data. It's 8,000 terabytes. That's 8,000 of your typical laptop storage. It's 1 million gigabytes. It's huge.

On top of the sheer size of the data, there's 2.4 million files. How do you analyze the data contained in all of these files?
The Current State of Affairs
I keep hearing that this is a "cloud scale" problem. I've talked to many commercial providers of analytics software and solution providers. Here's the generalized solution which appears to represent the state of the art.
- Parse all of the data into some other format which makes it easier to import to a database or data store of some kind. The industry appears to love JSON flavors as the destination format.
- Setup a cluster of databases, data stores, data lakes. Why not data oceans?
- Using various abstraction layers and clustering systems, analyze the data using commercial analytics tools.
- Throw away the 8 PB source log files now that the Map/Reduce and Extract/Transform/Load parts are done.
Let's walk through these steps. Each vendor and each solution are completely logical. It just happens to be tangential that every provider will make huge profits on handling this data. The quotes are i the millions, if not tens of millions.

Parsing the Data
The log files are all semi-structured log files, think along the lines of syslog. Multiple custom apps have logged to these files, so there are differing formats contained in each file. I say semi-structured because one can quickly determine the patterns of each app. The formats are all space delimited and pretty easy to figure out. It's just, there's trillions of lines to parse.
Where to store the parsed data? We could write the resulting parsed data to other files. Even at 10x reduction, we're still talking 800 TB of parsed data to handle. We could have the parser write to a streaming system which then does further modifications to the stream of data before it deposits the results in some data store (database, data lake, data ocean, whatever). This leads us into how to store 800 TB of data.

Parsed Data Storage
Modern analytics systems need to query data in expected formats. The parsing system has to understand the source and destination formats. Really, you're just converting from one format to another. The industry loves JSON because you can define the format and create your own key:data scenario (aka key-value store). After the raw logs are into JSON format, another parser can be used to further convert the data into the desired destination format, such as SQL.
Say streaming it to the datastore seems the most popular solution. The industry sure loves their streaming solutions. Instead of writing to file systems, we just parse -> transform -> load into data system. It sounds great until something mid-stream fails. We're still working with 800 TB of data. Lots will fail.
The data store itself is also huge. If the raw parsed data is 800 TB, with indexes and overhead of the database system, it's back to a petabyte or so.
Let's recap. We've taken 8 PB, extracted what we want out of it, down to 800 TB. We're at a total of 8.8 PB of data now. With data storage overhead, assuming SQL servers, NoSQL servers, distributed data lakes, etc, we're around 9.5 PB of data. We haven't started to analyze anything yet.
Lateral Solutions
At some level, the data is already in a structured format as it sits on disk in log files. Rather than all this Map/Reduce/ETL stuff, can we just build indexes directly off the raw log files?
Yes. Yes we can. AWS Athena can do this off data in S3. Here's how much it costs per query:
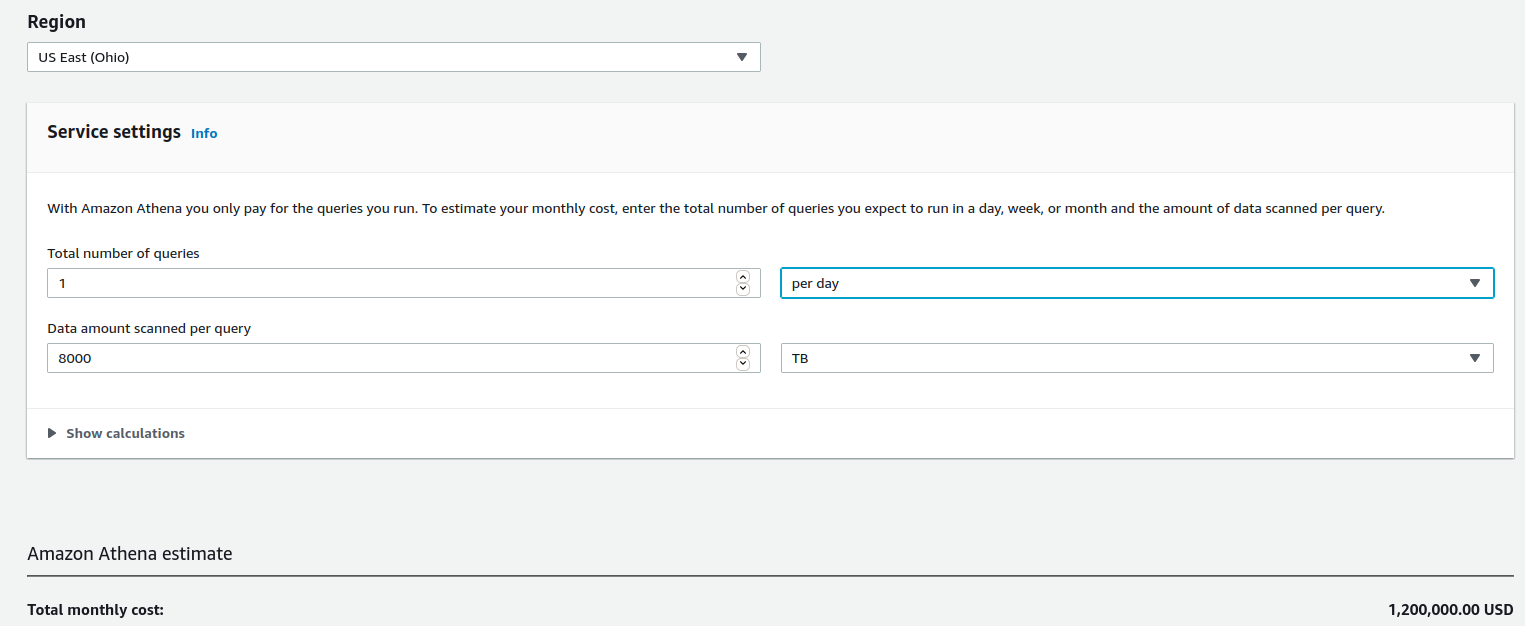
At list price, $1.2m/query. Say we're going to make a few thousand queries a day, we quickly get into the billions. This is the per day cost. There are still data transfer charges to get the data out of the datacenter and into AWS S3, so we can use Athena. Ok, this is just throwing away money.

We start looking at building binary data stores, aka indexes. I don't want to load 8 PB of raw log data into a search engine, so it can build indexes. I want to build indexes off the raw log data. It's highly repetitive, UTF-8 compliant data. I then want to search those indexes.
This takes me into theories of computing and O(log n) time and query efficiency. It's a fascinating new world. As said at the start, there is no solution. Building indexes off raw log data is the current plan. A filesystem as database would be a neat thing to have now. There is prior work on this topic.
Let's think more lateral about possible solutions. A quick brainstorming session results in these:
- do nothing and don't analyze the data (then why are we keeping it?)
- delete it and the problem is gone (then why are we keeping it?)
- create a new database or document file system and move the logs to it
- build binary indexes for each log file and then indexes of indexes for parallel querying
- load everything into a data lake, use Hadoop/Hive to query
- parse the data to an intermediary format for loading into current analytic systems
- look into quantum computing and the ability to query all of the data at once through superposition and some sort of sub-atomic magic
- build our own cloud to replicate AWS Athena functionality
- create a Kaggle competition and let smarter people figure it out
- fund academic grants and let smarter people figure it out
- use mechanical turk/cheap labor to sort and parse the data
- build a crawler/search engine on Elastic Search/Solr/MongoDB and query with existing tools.
- develop a time machine to go back in time and rewrite the logging system to use a more structured format
- develop a time machine to go forward in time and see how we solved the challenge
- pretend no one saw the 8 PB filesystem
And we're back to square one. We have 8 petabytes of log files and need to analyze them. Ta da!
