Debugging a Problem of My Own Making
Or, how my love of IPv6 messed up my network for a year.
Primary Issue
My home network is mostly FreeBSD and IPv6-first. IPv6 first is actually what the specification mandates. I built a fully-functional IPv6-only network at first. Unfortunately, wide swaths of the Internet require IPv4. As much as I'd like to just not go there, others want access to this legacy space. I setup a 6-to-4 gateway which translates internal IPv6-only network to IPv4 on the outside. I also setup DNS64 for the internal server so that domains without a IPv6 address, could have one for the 6-to-4 gateway. However, I gave in and setup IPv4 DHCP on the home network and just use NAT to let the internal, private network clients talk to the rest of the world. Pretty standard setup that everyone does these days.
Every once in a while, I'd notice a request would take forever to continue. And by forever, I mean 30 second lags. I could never quite figure it out from packets captures. And it happened so infrequently, I just put in the pile of things to investigate when I had time. That is, until I setup a FreeBSD jail and tried to use lynx to browse sites. If you haven't heard of lynx, it looks like this:
It's a text browser without javascript. It is really, really nice to read the content without all the unrelated imagery associated with most sites today. And finally, the lag on request to some sites was really annoying. Why some sites and not others?
I would fire up curl and make a request to the laggy site in milliseconds. Hmm. I spent way too much time looking at logs on the firewall and at packet captures. Only to find everything but what I wanted to find. I saw my lynx requests for the target site, say https://brutalist.report. The DNS lookup, the response with the 64:ff IPv6 from the DNS server and the subsequent TCP connect request. The odd thing is the TCP connect just hung for like a minute. But curl request worked instantly, so....?
I did what any sane person would do, I fired up truss and watched every system call from lynx to see what was happening. Here's the start of the truss output:
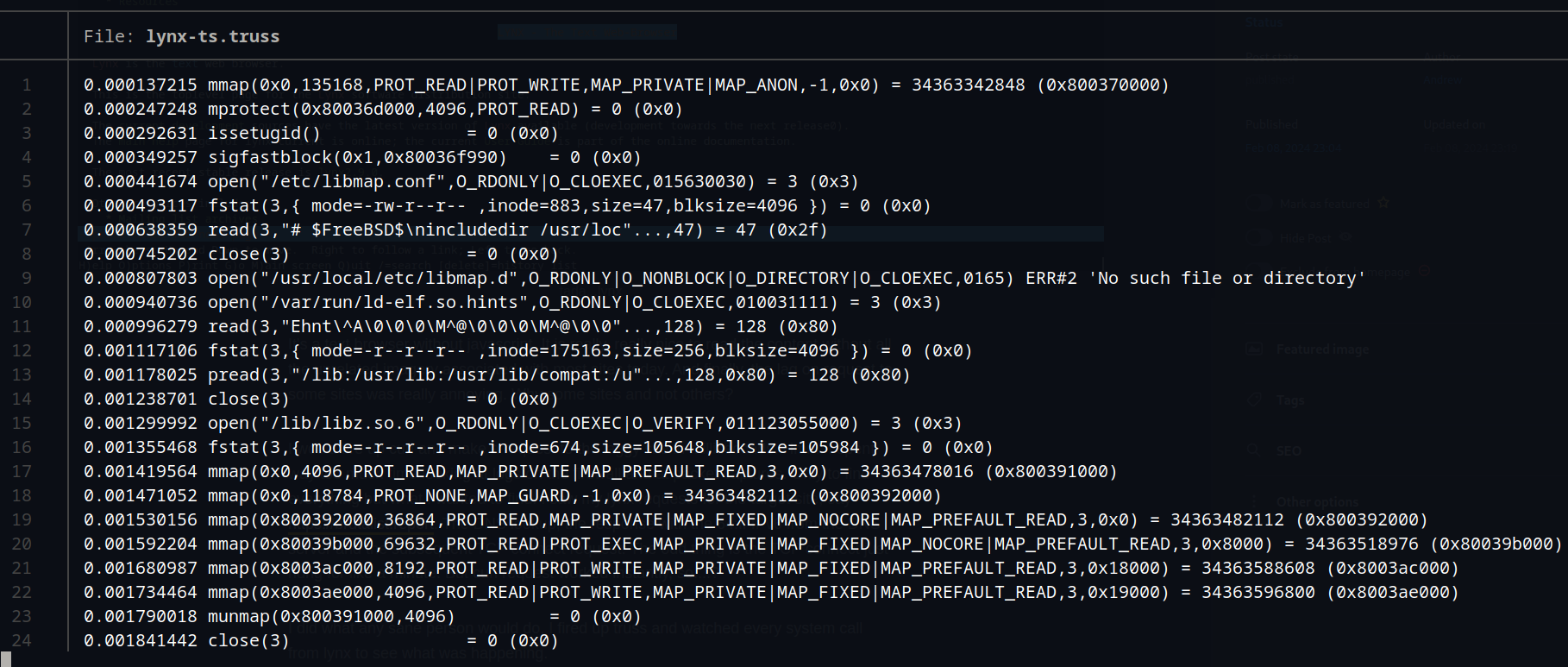
What you're looking at is elapsed time on the left and then the actual system calls (syscalls) and their data. Here's the lookup and request for the default website, lynx.invisible-island.net:
0.032441984 write(1,"\^[[39;49m\^[[39;49m\^[[38;5;7m"...,41) = 41 (0x29)Yes, that's 0.03 seconds since starting lynx. And here is lynx creating the socket to open the TCP connection to the website:
0.239560824 socket(PF_INET6,SOCK_STREAM,IPPROTO_TCP) = 3 (0x3)Pretty straight forward so far. And here's the actual request for the TCP connect:
0.239756507 connect(3,{ AF_INET6 [64:ff9b::c07c:f99e]:443 },28) ERR#36 'Operation now in progress'It's not actually an error, but it's just how the C library works. The point here is it's making an IPv6 connection to [64:ff9b::c07c:f99e]:443 which is IPv6 address "64:ff9b::c07c:f99e" on port 443. Ok, seems normal for a https request. Although, something in the back of my head said, "64:ff9b" seems familiar and odd. Even more odd, is it makes this request 736 more times over 75 seconds--75.25 seconds to be exact---well, 75.253190955 seconds to be accurate. Here's where it finally gives up:
75.253190955 connect(3,{ AF_INET6 [64:ff9b::c07c:f99e]:443 },28) ERR#61 'Connection refused'So, it cannot connect to the IPv6 address and then makes an IPv4 request:
75.253931680 connect(3,{ AF_INET 192.124.249.158:443 },16) ERR#36 'Operation now in progress'2683
75.256503272 select(4,0x0,{ 3 },0x0,{ 0.100000 }) = 1 (0x1)2684
75.256723442 connect(3,{ AF_INET 192.124.249.158:443 },16) ERR#56 'Socket is already connected'This IPv4 request and connection happens quickly, let's round up and call is 0.003 seconds (in reality it is 0.0027999999999934744 seconds elapsed).
Let's go back to that IPv6 address, "64:ff9b::c07c:f99e". Let's look it up only to find it doesn't resolve. Hmm. I did what anyone would do, search for it on the Internet, and I find https://www.rfc-editor.org/rfc/rfc8215.html. And in there is this in the literal first sentence of the RFC:
This document reserves 64:ff9b:1::/48 for local use within domains
that enable IPv4/IPv6 translation mechanisms.
Well....duh. That's why 64:ff9b looked familiar to me, it's a non-routable address for internal use only.
Ok. Where did it come from? When I did a dns resolution for the AAAA record for brutalist.report or lynx.invisble-island.net, I get a response which we saw above. Why is my DNS server doing this? It should just return an empty result.
My 6th sentence in this blog post is why. DNS64 creates an address in the 64:99fb range when a domain doesn't have an IPv6 address. The simple fix is...just disable DNS64 in the DNS server.
Why did curl work?
Well, because by default curl uses IPv4, so it was never a fair comparison nor test of reachability.
And now everything is fast again. Someday every site will have IPv6-only, we can dream. I've been waiting for this since the 1990s.
Secondary Issue
While spelunking packet captures, I find many hosts on the network take 1-2 seconds to resolve a domain name to an IP address. This raised the question, why is DNS slow? Even if the answer is already in DNS cache, it would still take up to 0.5 seconds to resolve. This should be quicker. 0.5 seconds is just long enough to notice, nevermind 1-2 seconds, as you wait for the page to load, or connection to happen.
I dug into a few hosts on the network. They were all configured to use systemd-resolved for name resolution. I configured it to use DNSSEC and DNS over TLS from the host to the DNS server on the network. As a test, I removed system-resolved and let resolvconf handle configuring /etc/resolv.conf directly, Therefore, all DNS lookups went raw to the network DNS server. These name resolutions now complete in under 5 milliseconds, on average. From the user experience, the sites are instant. Given the average site asks for like 10 domains, before it even starts to display the web page, the drop in time from even 0.5 seconds to 0.005 seconds per domain is noticeable.
drill brutalist.report
;; ->>HEADER<<- opcode: QUERY, rcode: NOERROR, id: 46507
;; flags: qr rd ra ; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;; brutalist.report. IN A
;; ANSWER SECTION:
brutalist.report. 192 IN A 45.32.206.215
;; AUTHORITY SECTION:
;; ADDITIONAL SECTION:
;; Query time: 3 msecEven if I query with DNSSEC forced, it's still only 5 ms:
drill -D brutalist.report
;; ->>HEADER<<- opcode: QUERY, rcode: NOERROR, id: 34914
;; flags: qr rd ra ; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;; brutalist.report. IN A
;; ANSWER SECTION:
brutalist.report. 110 IN A 45.32.206.215
;; AUTHORITY SECTION:
;; ADDITIONAL SECTION:
;; Query time: 5 msec
;; EDNS: version 0; flags: do ; udp: 1232If I can't trust my own network, then I should give up. Every host is connected over wireuguard to the VPN server, over either Ethernet or WPA-3 Encrypted 802.3 wireless. I already have basic zerotrust in place with the wireguard connection...in case my wifi or network is compromised somehow.
And there we go, solved 2 issues with one set of debugging.
