Useless Google Takeout

With the imminent demise of Google+, I figured now is the time to export my data and import original posts to this blog. Simple thought, complex implementation.
Step One: Get your data
It's trivially easy to find instructions on the Internet about how to select and download your data through Google Takeout. Basically, go to Google Takeout, choose Select None, and scroll down the page and find Google+ Stream. Move the little slider on the right to the right and choose your format, either HTML or JSON. This is the easy part. I have 2.8 GB of data in HTML now. I did it again to grab it in JSON. I figured JSON is easier to parse and therefore quicker to re-create the Google+ posts into this blog. So, let's begin.
Step Two: WTF is this?
Unzipping the JSON file results in thousands of files, specifically at least three text files per post, and then there's the images tied to each post. The three text files appear to be a JSON dump of the post and some metadata, a metadata comma delimited file of metadata about the post, and then a metadata comma delimited file about each image included in a post. In some world, this makes sense, so let's just keep going.
At the root of the extracted folders is an index.html file. This displays a nice start page for your posts, or so I hoped. Here it is below:
Being curious, I clicked on "Learn more", it takes you to this support answer, https://support.google.com/accounts/answer/3024190. Not very helpful.
Ok, so click on "Google+ Stream", which brings up this page:
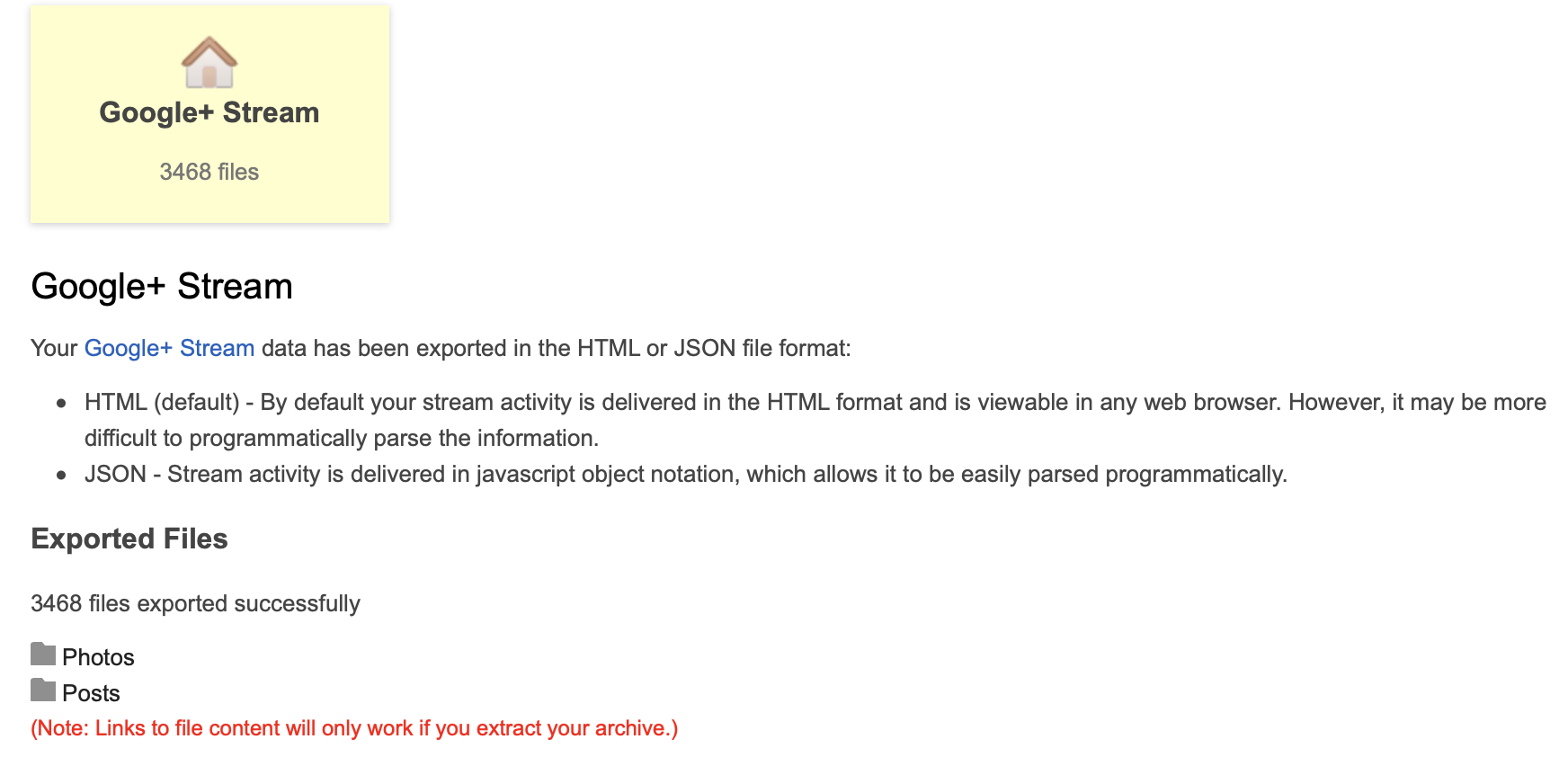
The key phrase there is:
"By default your stream activity is delivered in the HTML format and is viewable in any web browser. However, it may be more difficult to programmatically parse the information."
My entire goal is to programmatically parse the information, so I went back and got the JSON export. It turns out, the folders of "Photos" and "Posts" are just directory listings. So I started down the path of parsing the JSON files to recreate the posts.
Here's a simple example of the JSON about a post:
{
"url": "https://plus.google.com/+AndrewLewmanWorld/posts/JXbkbYrn12z",
"creationTime": "2016-05-09 16:28:18-0400",
"updateTime": "2016-05-09 16:28:18-0400",
"author": {
"displayName": "Andrew Lewman",
"profilePageUrl": "https://plus.google.com/+AndrewLewmanWorld",
"avatarImageUrl": "https://lh3.googleusercontent.com/-YVE3sCPoFIU/AAAAAAAAAAI/AAAAAAAAABU/joKQn9tdhCk/s64-c/photo.jpg",
},
"content": "Speaking at \u0026quot;Inside the Dark Web\u0026quot; this week. \u003cbr\u003e\u003cbr\u003e\u003ca rel\u003d\"nofollow\" target\u003d\"_blank\" href\u003d\"https://lnkd.in/bWJw5F8\" class\u003d\"ot-anchor bidi_isolate\" jslog\u003d\"10929; track:click\" dir\u003d\"ltr\"\u003ehttps://lnkd.in/bWJw5F8\u003c/a\u003e",
"link": {
"title": "INSIDE DARK WEB PREMIERES IN NEW YORK CITY - Dark Web conference 2016",
"url": "https://lnkd.in/bWJw5F8",
"imageUrl": "http://images.tmcnet.com/tmc/darkweb/images/alan-m.png"
},
"postAcl": {
"visibleToStandardAcl": {
"circles": [{
"type": "CIRCLE_TYPE_PUBLIC"
}]
}
}
}
Most of that is pretty easy to parse with nearly any JSON tool. The "content" field is not, because it includes snippets of html, escaped text, and in other posts, seemingly encoded text (base64, unicode, hex, and who knows what else). This is a simple example. It appears over the 3000+ JSON files, some are more complex and the whole set is complex.
Step 3: The content: challenge
I spent some time hacking up solutions to handle the content field. The assumption that while it's messy, it's at least produced by some Google tool which exports data the same way every time. That would be a poor assumption. After spending an afternoon hacking away, I figured I had real work to do and put it aside. I then hired a few coders who wanted the challenge. Three have quit saying it's probably faster to hire people on Mechanical Turk to manually re-create the posts than it is to programmatically do the same.
I have some scripts which take care of matching the JSON file with the metadata and find the images associated with the posts. That's the easy part. Converting all of this into Markdown to import into this blog is where everything came to a standstill. I have two more coders cranking away at it. I'll let you know as we progress.
Plan B is to just scrape the existing posts while they're still available and see how much I can convert to Markdown via that method.
Step 4: Migration vs Abandonment
The whole idea here is that I want to migrate my content from dead networks into something I control and can keep alive. This blog starts in 1998. In fact, it existed for 4 years before that, initially as .plan file updates (accessible by finger) and converted to gopher and then as html updates for NCSA Mosaic users. The most common solution is to simply abandon the content and leave it as a point in time until it's taken down, like Geocities, MySpace, etc. This latter path is what I took when I left my shell server and lost the files. It was 1994 and I figured who cares about the content I wrote back then. Of course, re-reading some of the older posts, I begin to wonder how valuable it all is too. However, preserving history and not having to pull it out of the Wayback Machine seems like something worthwhile.
The larger point is that taking your data out of platforms is great and all, but if you can't do anything with it, then you're just as locked in as before.